Code quality matters

In the modern age of big data, data science solutions are entering ever new fields. The market is literally over-saturated with start-ups, which daily generate new and modern ideas on how to extract even more from data. So, it’s surprising that ML hasn’t taken over the business of all major corporations yet, and it’s even harder to understand how it’s possible that most of the solutions promising a brilliant tomorrow will eventually be erased from history.
3 REASONS TO THROW OUT DS SOLUTIONS (AND START OVER)
If we look at any book on data science, it is written in bold with the GIGO warning, i.e., the principle of garbage-in, garbage-out. In other words, if you base your solution on misleading input data, then the results will be misleading. Clear and simple. There’s nothing wrong with that, is there?
But the sad truth that many overlook is the fact that success doesn’t just depend on good input. To get really valuable output, I have to control the whole process.
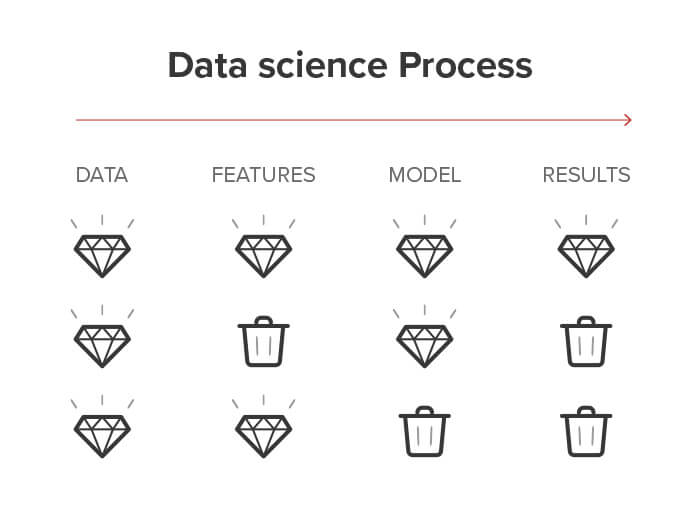
What can go wrong? Lots of things. The individual things that cause a painful clash with reality can be divided into three groups.
1) Non-replicable
Just because a solution works in vitro does not mean that it will be vital in a real environment. There can be a number of problems, from statistical problems (e.g., overfitting: i.e., being too tightly bound to known data) to market turbulence (see, e.g., how Covid-19 has unexpectedly mixed things up). Unfortunately, the most common reason for problems is much simpler—undetected and unresolved errors from the development of DS solutions.
There are, of course, a number of such mistakes. Let’s at least name the most feared one: data leaks. When processing the input data and learning the model, it is dangerously easy to inadvertently “reveal” something about the expected response to the features. Such “extra-informed” features then, of course, work first in the learning phase. However, in a real deployment, their unauthorized advantage is not available and the resulting model is completely toothless.
In short, if there is an error in data processing, the result is inevitably wrong. And it doesn’t have to be an unwanted information leak. So, it is absolutely essential to have a process in place that reveals all problems in time.
2) Non-transferable
Have you ever asked your supplier how the model they offer you actually works? And did you get a clear answer? I’m not just talking about the tricky use of black-box frameworks (whose dangers I wrote about here). When you look under the hood of the supplied solution, you should see a well-lubricated, working piece of software. Not to mention documentation, code versioning or performance logging of past ML model runs.
If you find yourself recoiling in horror when you look at the source code, don’t hesitate, run. Tuning and especially maintaining such a model is truly a nightmare. I’d really rather force a tear, learn more, throw it away and start over.
3) Model deployment? Sorry, we don’t do that…
And finally, the third big pain—the inability of creators to deliver their solution and, above all, make it last. On one hand, this is an essential requirement of every business owner—otherwise, the data science solution would hardly be beneficial. On the other hand, the deployment and subsequent maintenance of the model are diametrically opposed to what data science people usually do and enjoy—finding and discovering patterns in data.
Deploying a model with everything requires craftsmanship in another profession—software engineering. If it’s not done correctly, the contracting authority cries over the earnings. The deployment and maintenance phase of the model is often somehow “forgotten” or this necessary step is simply passed on to the customer.
A DS SOLUTION IS A SOFTWARE CREATION
Somewhere inside every data science product beats an ML widget (understand: ML model). It’s this core that allows you to do all those great things such as recognizing an oncoming car and issuing a brake command in time.
But all around this ML, there is a large amount of “regular code”. This code keeps the kernel alive (understand: it procures and properly prepares inputs, runs the ML kernel, communicates with the client, saves the results and so on). Without a good skeleton, the best ML core could slide… It’s no coincidence that data science emerged as multidisciplinary, lying on the border between mathematical statistics and computer science.
And now, I have good news for you. Software engineers have had a recipe for all the ills described in the previous chapter for many years (or rather decades). The secret recipe is, of course, a proper and well-maintained software process.
This also includes the discipline of quality assurance, which has set itself the difficult, but all the more important, task of ensuring that the solution delivered is not thrown away but kept. So, exactly what we’ve been after since the beginning of the article. Excellent!
Yes, it is necessary to add suitable control of that ML core to the QA commonly practised—i.e., the whole process of training and validating the ML model and its performance. So-called MLops tools can successfully be used for this, which we’ll discuss in one of the next articles.
HOW WE DO DATA SCIENCE AT PROFINIT
Although the solution exists and has successfully been used by software engineers for many years, it has been penetrating the data science field only gradually and very slowly. It’s actually quite sad, considering the low-quality products that are created. Products that cast a bad light on the entire data science industry by failing to raise expectations. And that’s a shame!
At Profinit, we have the advantage of building data science and big data competencies on the solid foundations of an established IT company. All of us go through intensive training. We also pass on our know-how by teaching several subjects at universities in Prague (the Czech Technical University in Prague and Charles University). So, I hope that the trend of uncontrolled DS shots in the dark will change over time and will not embarrass our field.
And most importantly, I hope to successfully reach my goal the next time I rely on an ML solution.