Spark AI Summit – what is new in the world of big data?

First of all, I want to thank Databricks for making this virtual conference happen and making it free for everyone. Great talks, great organization, very good conference platform!
Before we dive into releases, I want to highlight one fact. Python is the most used language in the Databricks platform. If you have been working in big data for some time, you have probably had this discussion at least once. Scala/Java or Python? Which language should I choose for my big data processing? Well, the numbers speak for themselves.
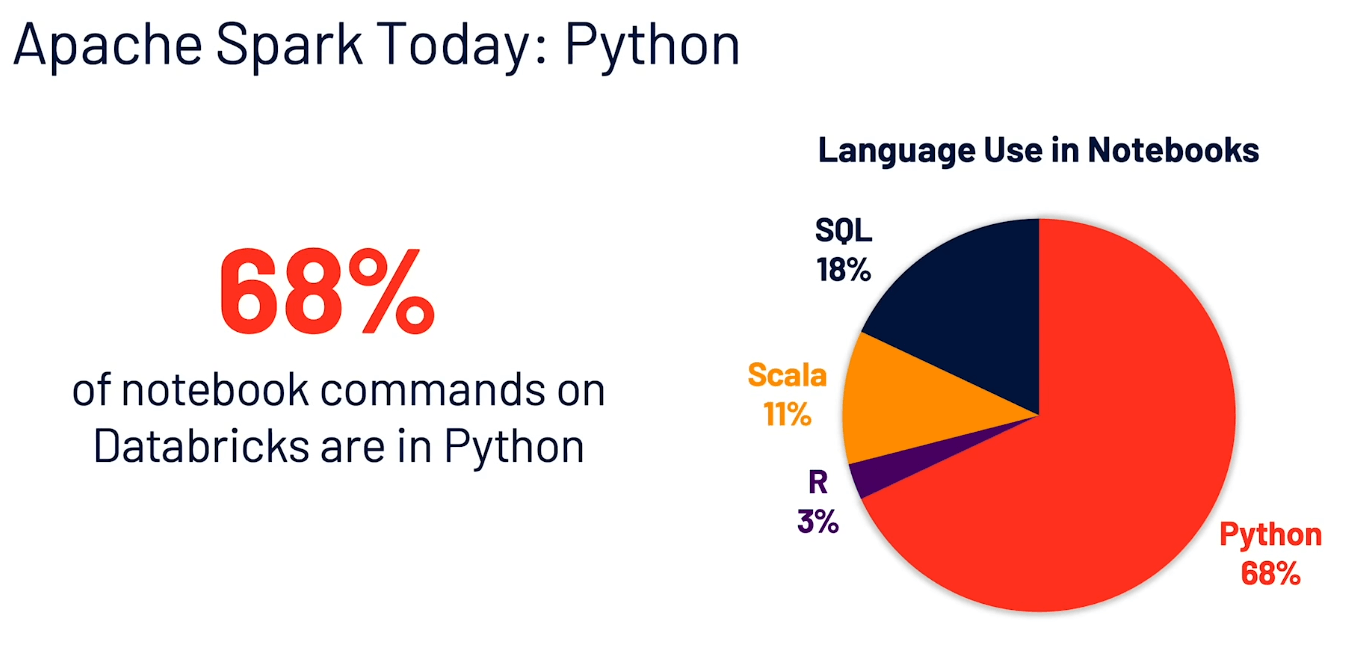
Why is this important? First of all, it’s okay to use Python for big data processing. Secondly, two-thirds of users are using Python, so we are going to get better support and new features for Python in the future.
For all who are interested, here is the entire presentation on Apache Spark 3.0:
As for me, I want to highlight three technologies that were mentioned during the conference because I think they are cool and a sign that the field of big data is moving forward.
Spark 3.0
Apache Spark is maturing from being THE big data processing framework into being a data processing ecosystem. It seems like the technology is stable and feature-rich enough. The authors can now focus on building a data processing ecosystem. At this stage, the main goals of the project are stability and optimization. You get rid of things that do not work and make the rest better and faster. This is what Spark 3.0 brings us. Notable changes (from my point of view):
- Adaptive query execution (AQE). By gathering runtime statistics, Spark can now update the query plan at runtime. For example, if the number of rows/bytes in the stage is small, Spark can adjust the number of reducers in the next stage, which leads to better resource utilization and solves the “many small files” problem.
- Redesigned Pandas UDF. Spark 3.0 introduces a more pythonic way of defining a Pandas UDF using type annotations. You can also implement a custom aggregate function in Pandas using the applyInPandas function.
- Spark Structured Streaming UI and Prometheus support. Operating Spark jobs always was a challenge. It was even harder in Python. Running a streaming job in Python was almost impossible. New functionality makes operating streaming jobs more transparent and integrates the great open source monitoring framework Prometheus.
Delta Lake

Changes in machine-learning model data can last a significant amount of time in more than just Kaggle competitions. What if you need to delete a customer from a big data table? How can you update a customer record? These questions aren’t easy to answer with big data platforms.
Since its introduction, Hadoop was designed as a write-once/read-many system. You had to re-run batch jobs to update or to delete a single record from a table. Recent developments in the field of big data have taught us that this assumption was insufficient. In light of GDPR, we need to be able to delete a customer in a reasonable amount of time from our data warehouse without reprocessing a whole table at every request.
This is where Delta Lake can help us. It is a storage layer on top of Apache Spark that introduces ACID transactions and data versioning. It does not require additional infrastructure, just add an extra dependency and start writing your data in delta format. Behind the scenes, Delta uses the Parquet file format and stores the metadata on HDFS. With Delta, you can implement upserts and change data capture processing on Hadoop without much effort.
Koalas

Last but not least, Koalas. Let’s say you already do some Python/Pandas data processing and want to try big data processing. A year ago, this meant that you would have to learn a different set of APIs to do things you already know. This also meant a completely different workflow. It does not have to be this way with Koalas.
Koalas is a project that aims to scale your Python data processing pipelines from a single node to a big data cluster with just a single line of code. Just type import Koalas instead of import Pandas and you’re done! Check out the Getting Started tutorial in Koalas’ documentation.
And of course, there were many more interesting ideas that I would love to write about. So, stay tuned for our future blogs, and do not hesitate to get in touch to talk about where you are and where you want to go on your big data journey.
Related topics: 7 tips on how to fix a large amount of data in Hadoop