3 Data Science Process Challenges

Graduating students hope that they will create a new recommendation system or search ranking algorithm. In reality, they have to deal with missing data, scalability and integration issues. On top of that, they have to learn the company’s processes or build new ones. It is no surprise that school is different from the working environment, but the data science field has unique challenges. In this post, I want to describe a few things I have learned in recent years.
Am I doing it right?
One of the key differences between learning and working environments is the amount of uncertainty involved. When you are solving a problem in a school or a course, you’re likely to be presented with a clear objective and instructions on how to accomplish the goal. Here is a dataset. Here is a metric. This is an optimal solution. Use these and those methods.
Whoa, welcome to the new world of applied data science. You don’t know what the best metric for the problem is. You don’t know which algorithm is the best. You don’t know what the best possible score is. The good thing is that nobody does.
Agile methodology offers a nice way to cope with such uncertainty. It helps you and your team react to changes in a reasonable amount of time. You should regularly revisit your goals and update them with new information.
Do you believe your data?
The first thing I learned as a practicing data scientist is that you can’t blindly trust the data. It’s so easy to make this mistake. Machine learning and data science courses are all about well-known domain problems and industry-standard datasets. There is the titanic dataset for classification, house-price dataset for regression, and MNIST for neural networks. Compare them to your company dataset.
Here are just a few of the problems I encountered last week.
- User-generated data. It’s a huge mess. Humans are highly creative in naming the same thing in many different ways. Making sense of this partially-structured data is a very time-consuming process. And it’s dull. After all, I’m here to deliver insights, not to analyse how the word “account” might be spelt in 50 ways. The amount of manual work is underestimated.
- The data is just not there. The worst type of data is data you don’t have. Maybe there is a bug or a peculiar behaviour in the software producing the data that requires extra care. For example, a cancelled transaction appears as the same transaction but with the price entered as a negative number. Another example would be a log capturing system that systematically drops “insignificant” events because they are irrelevant to billing.
- The data is inconsistent. The latest release changed the way your company identifies a user or introduced a change to a website map or data pipeline. Now you are faced with a difficult question: What to do with the old data? Sometimes you can discard old data, sometimes you have to manually map old events to new ones.
Approach data understanding with great care. Write down and verify all the assumptions about data with business stakeholders. Remember that data is not an exact representation of the real world, but a mere approximation of it.
Your job is undone until it’s useful
Nobody: I need a fancy new neural network model that is as accurate as possible.
A model with a high-performing metric is a good start, but it is not the end. Now it’s time to build a reliable data pipeline. The final result may take many forms:
- A table in a database created daily
- A Dashboard with predictions for the next week
- Or a real-time stream processing fraud detection application
Whatever solution is needed, it requires significant engineering skills and effort. Things like git, unit-testing and code readability come into play. You can read more on this topic here. Google engineers estimate that machine learning core code makes only 5% of all code written.
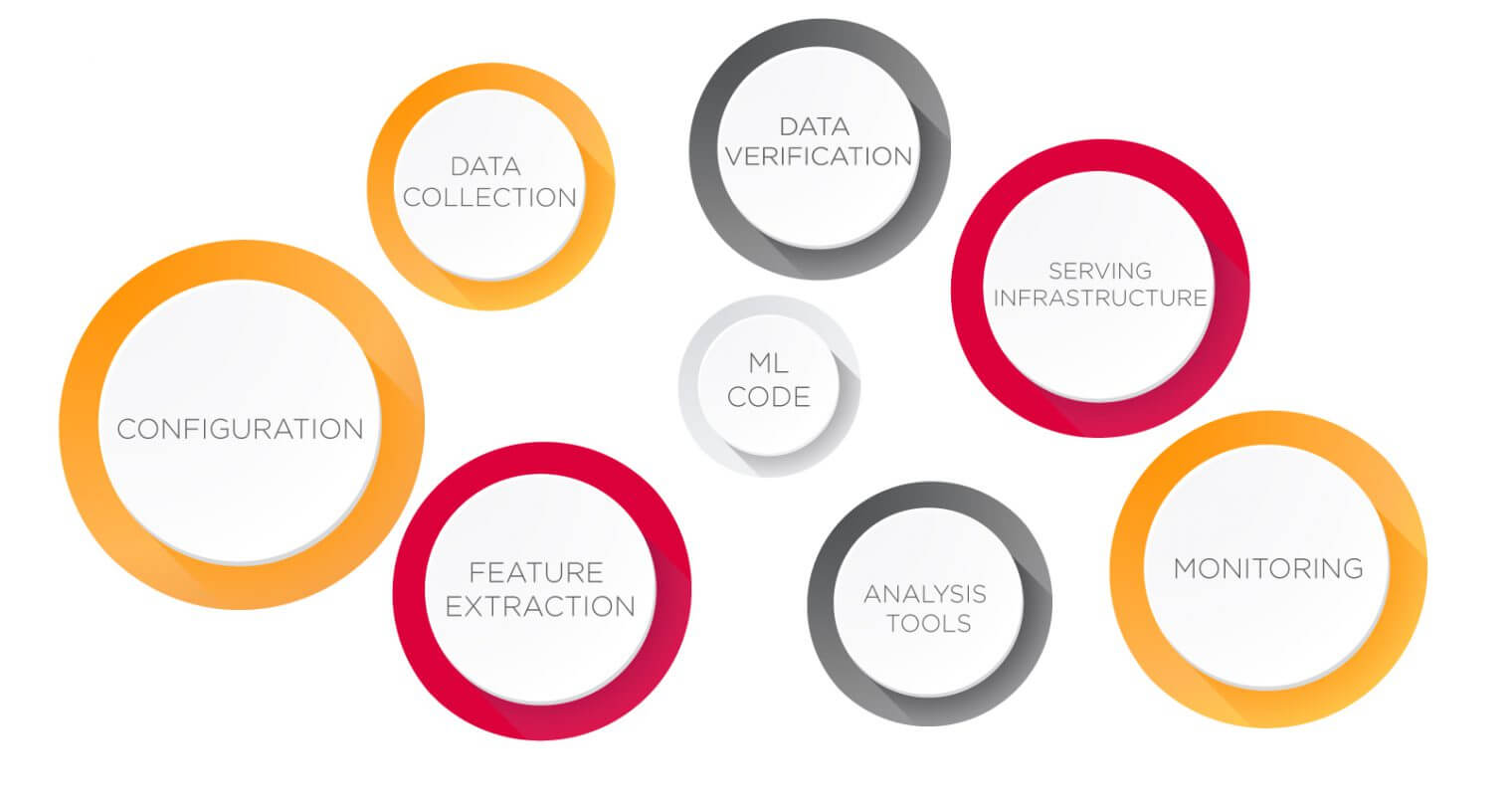
Make sure you invest some time into learning the basics of software engineering and introduce code reviews into your development process.
To wrap up, here are a few takeaways.
- Be pragmatic. You were hired to solve data-related tasks. That is how you are helping your company. A simple model working in production today is better than a fancy model working in a lab environment a month from now.
- Fiercely test your code. One more day of testing might save you and your company a lot of time and money in the future. Check out the Google Developers course on testing machine learning models.
- Giddy up. You will spend more time than you expect to examine and clean data
Are you still not sure how to approach data processing?
Ask us! Profinit will help you to build data science competence from scratch.